MMTEB: Embeddingのための新しい多言語ベンチマーク
2025-03-20
最近のEmbeddingモデルについて調べていて,MMTEB (Massive Multilingual Text Embedding Benchmark)という,Text Embeddingのための新しい多言語ベンチマークがリリースされていることを知った。前身のMTEBというベンチマークにタスクと言語をたくさん追加したものらしい。ICLR2025にアクセプトされたペーパーなので,かなり新しい。
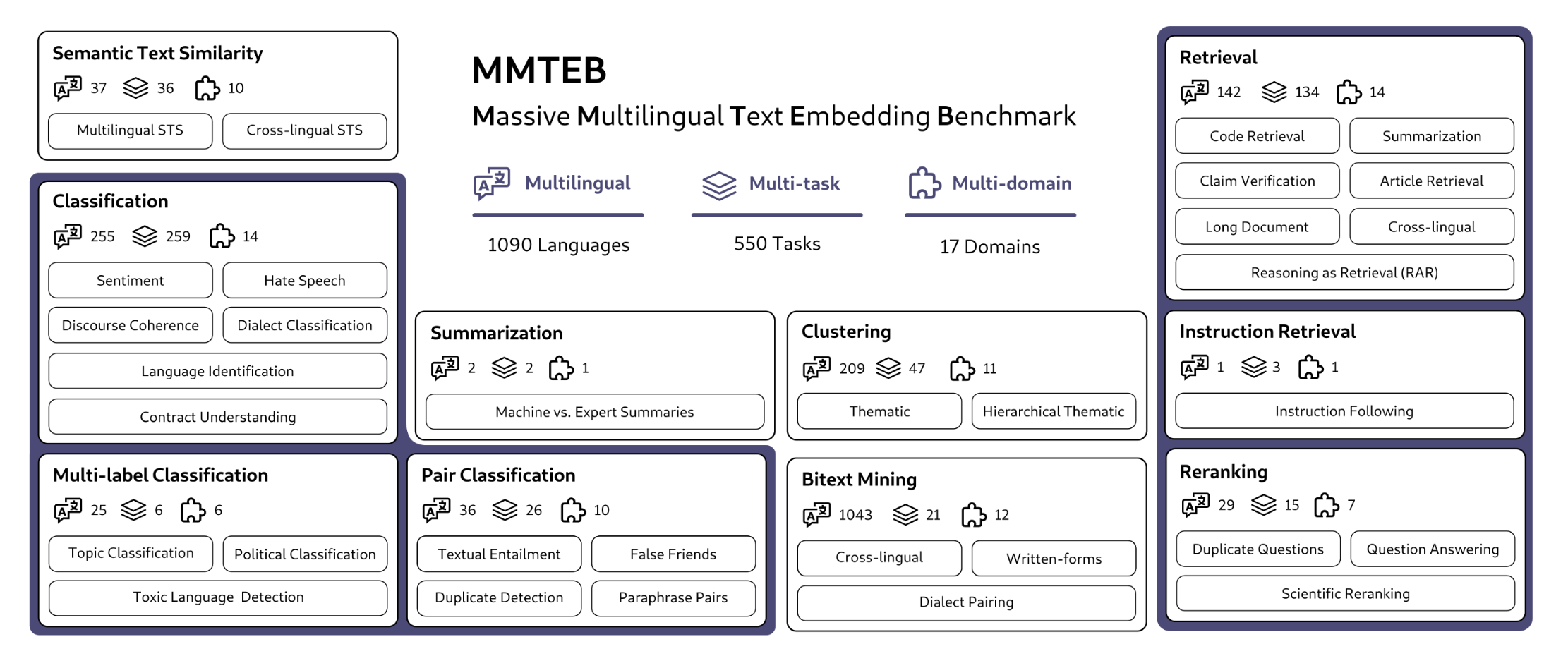
実世界のさまざまなユースケースと言語をカバーするため,10個のタスクカテゴリ(ファミリー)があり,タスクの総数は全部で500個以上,言語はBitextMiningで1050言語,その他のタスクカテゴリで250言語を含んでいる。Massiveを謳うだけあってかなりの規模。言語によってタスク数が異なり,日本語だと35タスクで入手できる。
リーダーボードを見ると,上位にはgemini-embedding-exp-03-07, Linq-Embed-Mistral, gte-Qwen2-7B-instruct, multilingual-e5-large-instructといったモデルが並んでいて(2025/3/20現在),SoTAモデルをさっと調べるのに良さそう。
文献をざっと眺めると,データセット構築手法に加えて,低コストでベンチマークを実行するためのdownsamplingにも触れられている(愚直に実行したら,embedding生成でものすごいコストがかかるらしい)。